Andreas Oberweis (Universität Frankfurt)
Klaus Pohl, Andy Schürr (RWTH Aachen)
Gottfried Vossen (Universität Münster)
Vom 11. bis 13. März 1998 fand an der Universität Münster der Workshop "Modellierung '98" statt. Dieser von den GI-Fachgruppen 0.0.1 Petri-Netze, 1.5.1 Knowledge Engineering (KE), 2.1.6 Requirements Engineering (RE), 2.1.9 Objekt-Orientierte Software-Entwicklung (OOSE), 2.5.2 Entwicklungsmethoden für Informationssysteme und deren Anwendung (EMISA), 5.1.1 Vorgehensmodelle für die betriebliche Anwendungsentwicklung und 5.2.1 Modellierung betrieblicher Informationssysteme (MobIS) gemeinsam veranstaltete Workshop hatte es sich zur Aufgabe gemacht, die mit Modellierung befaßten Fachgruppen der GI zusammenzubringen, um Gemeinsamkeiten, Defizite sowie Unterschiede in den verwendeten Modellierungsansätzen herauszuarbeiten und den gegenseitigen Erfahrungsaustausch zu stimulieren.
Diesen Zwecken entsprechend bestand das Programm aus sieben von Repräsentanten der Fachgruppen gehaltenen Übersichtvorträgen sowie aus 17 weiteren Beträgen, die von einem Programmkomitee unter Leitung von K. Pohl und A. Schürr (beide RWTH Aachen) aus 51 Einreichungen ausgewählt wurden. Wesentlich für alle Vorträge war die kurze eingeräumte Redezeit für die Vortragenden und die jeweils anschließenden ausführlichen Diskussionen. Ferner wurden die angenommenen Beiträge von Gegenrednern kommentiert; spezielle Diskussionszeiten hatten eine vertiefte Betrachtung einzelner Aspekte zum Ziel.
Im folgenden werden die Hauptaussagen aller Beiträge und der sich
anschließenden Diskussionen stark verkürzt wiedergegeben. Dabei
wurde das Schema des Workshops mit vier Sitzungen aus eingeladenen Vorträgen
und sechs technischen Sitzungen beibehalten. Die Tagungsbeiträge in
voller Länge wurden vor Beginn des Workshops als technischer Bericht
der Universität Münster veröffentlicht [PSV 98]. Zudem sind
das Programm des Workshops mit Postscriptdateien aller Beiträge und
Verweisen auf die WWW-Seiten der Workshop-Teilnehmer "online"
im Internet unter
http://SunSITE.Informatik.RWTH-Aachen.DE/Publications/CEUR-WS/Vol-9/
verfügbar.
Das Programm des ersten Tages umfaßte drei eingeladene und drei angenommene Beiträge. H.C. Mayr (Universität Klagenfurt) eröffnete als Vertreter der EMISA mit "Entwicklungsmethodologie für Informationssysteme: Wunsch und Wirklichkeit". Eine Betrachtung der fast 20-jährigen Geschichte der FG EMISA zeigt einerseits deutliche Entwicklungen: von der eher technisch orientierten Datenmodellierung über eine Einbeziehung der sogenannten "frühen Phasen" des Informationssystementwurfs bis hin zu einer immer stärker und wichtiger werdenden Einbeziehung des Anwenders in den Entwurfs- und Modellierungsprozeß. Andererseits fehlt nach wie vor eine "Konstruktionslehre" für Informationssysteme. Domänenwissen ist noch zu wenig vorhanden und kann dementsprechend noch nicht in angemessenem Umfang bei der Modellierung berücksichtigt werden. Abhilfe könnten hier z.B. "kleine" Modellierungssprachen schaffen, die auf einen bestimmten Anwendungsbereich hin abgestimmt sind. Entsprechendes gilt für einen Re-Use von Modellen, die besser an den Anwender, weniger an den Informatiker angepaßt werden müssen. Es zeigt sich heute ferner, daß unternehmensweite Datenmodellierung im wesentlichen gescheitert ist. Hauptgründe hierfür sind das Problem der Integration der verschiedenen unterschiedlichen Sichten auf das entstehende Schema sowie die kaum bewältigbare Komplexität der Aufgabenstellung.
G. Müller-Luschnat (FAST München) sprach für die FG 5.1.1 zum Thema "Der Geschäftsprozeß der Datenverarbeitung: Das Vorgehensmodell". Dabei ging es um den Prozeß der Entwicklung von Systemen der Informationstechnik, wobei der Begriff "Vorgehensmodell" als Synonym zu "Software-Prozeßmodell" oder auch "Anwendungsentwicklungsmodell" zu verstehen war. Im Vortrag wurde auf einschlägige Standards und entsprechende, z.B. auf Repositories basierende Werkzeuge verwiesen. Als noch aktuelle Probleme wurden die Integration objektorientierter Vorgehensweisen mit bisherigen Vorgehensmodellen sowie die Fülle von Abstraktions- und Meta-Ebenen in Modellen genannt, auf denen teilweise die verwendeten Methoden unbekannt sind. Eine zu hohe Detaillierung von Modellen sowie eine zu weit gehende Standardisierung berge zudem die Gefahr des Scheiterns in der Praxis in sich. Als Alternative wurde deshalb die Definition von Methoden-Fragmenten sowie die Entwicklung von Werkzeugen zum Einsatz solcher Fragmente genannt.
M. Jarke (RWTH Aachen) vertrat die FG RE mit "Anforderungsmodellierung: Können wir die Brücke zwischen Anwendung und Entwicklung stabilisieren?". Requirements Engineering ist essentiell interdisziplinär und versteht Redundanz sowie Inkonsistenz generell als Chance, Anforderungen in situationsgetriebenen Prozessen zu modellieren. Zunehmend in den Vordergrund treten dabei evolutionäre Aspekte wie Serviceorientierung, Organizational Learning, Absaugen von Kundenwissen (RE als Spezialdisziplin des Marketing), oder auch Traceability-Referenzmodelle, sowie die Einbeziehung multimedialer Szenarien. RE wird also nicht mehr als eine Aktivität, die am Anfang des Entwicklungsprozesses ausgeführt wird, angesehen, sondern als kontinuierliche Aufgabe aufgefaßt, deren Ziel die lebenszyklusübergreifende Wartung von Anforderungsmodellen ist. Die Unterstützung des Change-Managment ist daher, neben der Einigung der Beteiligten, der Anforderungsfindung sowie deren geeignete Definition, eine der zentralen Aufgaben des REs. Man unterscheidet zwischen notationszentrierten, domänenorientierten und themenorientierten Ansätzen. Es gibt enge Bezüge zum Knowledge Engineering, aber RE geht z.B. bei relevanten Domänen über KE hinaus.
Die anschließende Diskussion machte bereits zwei Dinge deutlich:
Erstens müssen Modelle domänenspezifisch werden und nicht länger
rein technische Aspekte in den Vordergrund stellen. Zweitens werden soziotechnische,
soziale, den Menschen und menschliche Interaktionen berücksichtigende
Modelle sowie die organisatorische Einbindung von Personen immer wichtiger.
Klar wurde ferner, daß diverse Begriffsklärungen vonnöten
sind, etwa den Begriff "Modell" betreffend: Was macht ein formales,
was ein halbformales, was ein abstraktes Modell aus? Technisch können
hier Anleihen in der Mathematik gemacht werden; aus der Sicht von Anwendern
und Anwendungen ist naturgemäß eine pragmatischere Sicht (z.B.
Verständlichkeit für Menschen) notwendig, die nicht allein auf
die Existenz von Beweiswerkzeugen Bezug nimmt. Allerdings geht es nicht
nur um die Unterscheidung formal vs. informal, sondern auch z.B. um formal
vs. material, speziell in den sogenannten frühen Phasen der Systementwicklung.
Es können auch Anleihen in der Philosophie oder aber unmittelbar im
Anwendungsbereich (Beispiel: Referenzmodell für das Handelsgesetzbuch)
gemacht werden. Wesentlich ist, für wen ein Modell gemacht wird, und
wer es zu welchem Zweck benutzen soll bzw. will. Wichtig ist ferner, auf
welcher Abstraktionsebene ein Modell angesiedelt wird, denn je spezifischer
diese Ebene hinsichtlich der betrachteten Anwendungsklasse ist, desto präziser
wird die Begriffswelt, und desto mehr klärt sich das ansonsten erkennbare
Dickicht homonymer Begriffe.
Der Vortrag von B. Paech (TU München) war ein "Plädoyer für ein einheitliches Grundgerüst bei der System- und Softwaremodellierung". Es wurde ein einheitliches Konzept vorgeschlagen, in dem Anwendungssystem, Nutzungssystem und Softwaresystem unterschieden werden. Alle Systeme weisen gemeinsame Konzepte (z.B. Ziel, Akteur, Rolle) auf; diese Konzepte bedürfen geeigneter Modellierungstechniken und führen schließlich zur Erstellung von Produkten. Generell verwendbar scheint ein aus der BWL stammender allgemeiner Modellbegriff nach Stachoviak zu sein; als Problem wurde in der anschließenden Diskussion angemerkt, daß Aufgaben- und Akteursebenen vermischt werden.
Im Vortrag von S. Strahringer (TU Darmstadt) wurde "Ein sprachbasierter Metamodellbegriff und seine Verallgemeinerung durch das Konzept des Metaisierungsprinzips" beschrieben, welcher ausgehend von einer Unterscheidung zwischen Metasprache und Metamodell auf eine prozeßbasierte vs. eine sprachbasierte Metamodellierung führt. Das vorgestellte Prinzip an sich läßt quasi beliebig viele Metaebenen zu; die ausgesprochen kontroverse Diskussion zeigte jedoch, daß nach Ansicht vieler Modellierer 3 bis 4 derartiger (Meta-)Ebenen ausreichen.
Im letzten Vortrag sprach R. Klischewski (Uni Hamburg) über "Modellierung
als Handgriff zur Wirklichkeit" und sprach die Empfehlung aus,
Modelle nicht nur als Werkzeuge zu betrachten, sondern in die jeweiligen
Prozesse unmittelbar einzubetten. Als Anforderung an eine Modellierung
ergab sich daraus unmittelbar eine Ausrichtung am sozialen Aspekt, die
situatives Handeln und Verändern ermöglicht.
E. Sinz (Universität Bamberg) sprach für die Fachgruppe 5.1.1 (MobIS) zum Thema "Modelllierung betrieblicher Informationssysteme: Gegenstand, Anforderungen und Lösungsansätze". Sinz betonte, daß bei der Modellierung ein Informationssystem (IS) als Teil eines betrieblichen Gesamtsystems angesehen werden muß, und daher die betrieblichen Ziele und der Beitrag des IS zum Gesamtsystem geeignet zu modellieren sind. Ein IS kann hierbei als "Nervensystem" eines betrieblichen Systems aufgefaßt werden. Ansätze zur IS-Modellierung müssen Unterstützung bei der Aufstellung umfassender, richtiger und geeigneter Modelle sowie Unterstützung bei der Bewältigung der Komplexität bieten. Ein Modellierungsansatz muß darüber hinaus geeignete Metaphern zur Verfügung stellen, um die praktische Anwendung zu ermöglichen. Als Beispiel für einen solchen Ansatz stellte Sinz den SOM-Ansatz vor, der die Definition des statischen und dynamischen Verhaltens sowie der statischen Struktur eines Systems unterstützt. Durch entsprechende Metamodellkonstrukte (Patterns) ermöglicht der Ansatz eine metamodellbasierte Adaption an domänenspezifische Bedürfnisse. Wie alle anderen Modellierungsansätze vernachlässigt der SOM-Ansatz die Modellierung der dynamischen Strukturaspekte. In der Diskussion wurde die Notwendigkeit der domänenspezifischen Adaption näher erläutert. Als Grund für die fehlende, aber benötigte, dynamische Sicht wurde zudem die Vernachlässigung der Organisation von betrieblichen Abläufen in der Vergangenheit bei der Modellierung von IS genannt. Als zusätzlicher Modellierungsaspekt wurde die dynamische Anpaßbarkeit der Ablaufbeschreibungen während der Laufzeit erwähnt. Um bei der Realisierung möglichst viel Freiheiten hinsichtlich der sozialen Aspekte des IS zu gewährleisten, sei zudem darauf zu achten, daß auf Geschäftsprozeßebene nur die für das fachliche Gerüst benötigten Einschränkungen getroffen werden.
Im Übersichtsvortrag "Objektorientierte Software-Entwicklung"
der Fachgruppe 2.1.9 (OOSE) stellte G. Engels (Universität-GH Paderborn)
Anfoderungen an (objektorientierte) Modellierungssprachen auf. Eine Sprache
sollte seiner Ansicht nach leicht verständlich sein, eine aspektweise
Modellierung ermöglichen, vollständig und konsistent bezüglich
der integrierten Aspekte (Verhalten, Struktur,....) sein, eine definierte
Semantik aufweisen, Wiederverwendung durch bspw. Vererbung unterstützen,
die Definition von Methodiken und Heuristiken ermöglichen und schließlich
leicht transformierbar sowie analysierbar hinsichtlich statischer und dynamischer
Aspekte sein. In der Diskussion wurde die Definition von Anforderungen
an Modellierungssprachen als sehr wichtig angesehen. Bezüglich der
vorgestellten Aspekte wurde angemerkt, daß die Anforderung an Transformierbarkeit
sehr unrealistisch erscheint, da das für eine Transformation in ausführbaren
Kode benötigte Wissen in den Modellen nicht enthalten sein kann (und
soll). Als weitere wichtige Anforderung wurden die Minimalitätsanforderung
(z.B. bezüglich der Anzahl verwendeter Teilmodelle und Sprachkonstrukte)
sowie die Notwendigkeit geeigneter Metaphern für eingesetzte Sprachkonstrukte
erwähnt. Zusätzlich wurde angemerkt, daß Notationen nur
sehr eingeschränkte Beiträge zur Wiederverwendung von Modellen
liefern können. Es wurde zudem stark angezweifelt, ob durch die Definition
einer formalen Semantik ein einheitliches Verstehen der Modelle erreicht
werden kann. Darüberhinaus wurde angemerkt, daß für die
Modellierung verschiedene Sprachen mit unterschiedlicher Abstraktion (abhängig
von den benötigten Sichten und Aspekten) eingesetzt werden sollten
und daher die Integrierbarkeit einer Sprache mit anderen Sprachen eine
weitere Anforderung darstellt.
Peter Rittgen (Universität Koblenz-Landau) stellte in seinem Vortrag "Zur Anreicherung von Modellierungsmethoden mit domänenspezifischem Wissen" den in Koblenz entwickelten MEMO-Ansatz vor, in dem drei Modellierungsebenen (Strategie, Organisation, Informationssystem) und fünf Foki (Resourcen, Struktur, Prozeß, Ziel, Umgebung) unterschieden werden. Da diese zwei Hauptaspekte orthogonal zueinander sind, sind für die Modellierung eines Systems maximal fünfzehn Aspekte durch geeignete (max. 15) Sprachen zu unterstützen. Während die Unterscheidung der drei Ebenen weite Zustimmung fand, wurde in der Diskussion die Komplexität des Ansatzes kritisiert. Die fünfzehn Aspekte resultieren nach Meinung der Zuhörerschaft in einer enormen Sprachkomplexität, so daß sich die Vermittlung der Sprache(n) als schwierig gestalten könnte. Ob die vorgestellte Komplexität zur Modellierung von IS benötigt wird, sei daher noch zu untersuchen. Zudem wurde ein Vergleich des Ansatzes mit ARIS oder SOM als wünschenswert genannt.
In seinem Vortrag "Towards an Enterprise Reference Scheme for Building Knowledge Management Systems" betonte Stefan Decker (Universität Karlsruhe) die zunehmende Wichtigkeit des Wissensmanagements für Unternehmen sowie das Fehlen einer methodischen Vorgehensweisen für die Definition und Entwicklung von wissensbasierten Systemen. Um die Modellierung und Entwicklung von Wissensmanagmentsystemen zu unterstützen und deren Auswirkung für die Organisation abzuschätzen, stellte Decker einen Baukastenansatz für die Modellierung von Wissensmanagmentsystemen vor. Der Ansatz beruht auf der modularen Definition von Methodenfragmenten und deren geeignete, aufgabenabhängige Komposition. In der Diskussion wurde das Problem des nicht modellierbaren, aber essentiellen taktischen Wissens angesprochen. Der Lösungsansatz einer fragmentbasierten Vorgehensweise fand weite Zustimmung. Es wurden jedoch Zweifel angemeldet, ob durch einen metamodellbasierten Ansatz die Komposition der Methodenfragmente erzielt werden kann. Zudem wurde angemerkt, daß im vorgestellten Ansatz die Definition von deklarativem Wissen durch die Verwendung von OMT nahezu ausgeschlossen wird.
Jörg Ritter (OFFIS, Oldenburg) vertrat in seinem Vortrag "Integration von Entwicklung und Einführung betrieblicher Standardanwendungssysteme durch Softwareproduktmodelle" die Position, daß die Softwareentwicklung sich weg von der Entwicklung von Individualsoftware hin zu parametrisierbaren und konfigurierbaren Anwendungssystemen bewegt. Während dieser Trend in der Praxis bereits zu beobachten sei, beschäftige sich die Forschung fast nur mit der Entwicklung von Individualsoftware. Um die Anpassung von Standardsoftwaresystemen an kundenspezifische Bedürfnisse zu ermöglichen, schlug Ritter deshalb die Definition von Softwareproduktmodellen vor, mit denen die Struktur und das Verhalten von kombinierbaren und konfigurierbaren Systemkomponenten beschrieben werden. Basierend auf diesen Modellen sei es dann die Aufgabe des Beraters (oder der Standardsoftwareanbieters) die kundenspezifische Konfiguration und Komposition vorzunehmen. Die Diskussion zeigte, daß es sich im vorgestellten Ansatz um einen ersten Lösungsvorschlag handelt. Konkrete Ideen für die Definition der Standardsoftwareproduktmodelle sowie für die Kombinierbarkeit der Komponenten sind noch in Entwicklung. Zudem wurde angemerkt, daß solche Modelle auch die Beziehungen zu Geschäfts(sub)prozessen herstellen müßten.
Die sich anschließende Diskussion konzentrierte sich auf komponentenbasierte
Modellierungs- und Softwareansätze. Für die derzeit vorhandenen
monolithischen Standardsoftwaresysteme wurden zwei Hauptgründe herausgearbeitet:
Einerseits bedingt die hoher Interdependenz auf Aufgabenebene monolithische
Systeme. Eine Aufteilung ist oft aus rein betriebswirtschaftlichen Gründen
nur schwer möglich. Andererseits wird die Integration von Systemen
immer enger. Zu der in den 80er Jahren vorherrschenden Datenintegration
kommt nun die Prozeß- und Kontrollintegration hinzu. Es bestand Übereinstimmung,
daß komponentenbasierte Ansätze unabdingbar sind, um die zunehmende
Komplexität bei der Erstellung (Anpassung) und Wartung von Softwaresystemen
in Zukunft beherrschbar zu machen. Bei der Definition von Komponenten sind
hierbei zwei Ebenen zu unterscheiden. Zum einen sind Komponenten unter
Berücksichtigung der in ihnen realisierten Funktionalität aus
Anwendersicht zu modellieren. Hierdurch wird die aufgabenbezogene Kombinierbarkeit
von Komponenten erst ermöglicht. Dieser Aspekt wird von existierenden
und auf Datenintegration ausgelegten Referenzmodellen - wie beispielweise
ARIS oder SAP R3 - vernachlässigt. Zum anderen sind die Komponentenschnittstellen
geeignet zu definieren, um deren Kombinierbarkeit zu komplexen Softwaresystemen
zu ermöglichen. Es wurde übereinstimmend festgestellt, daß
derzeit sowohl Kombinierbarkeitskriterien fehlen als auch eine klare Vorstellung
darüber, welche Eigenschaften einer Komponente an der Schnittstelle
zu definieren sind. Als logische Konsequenz existiert derzeit keine geeignete
Komponentenbeschreibungssprache.
Ulrich Reimer (Swiss Life, Zürich) sprach für die Fachgruppe 1.5.1 (KE) über "Vom Knowledge Engineering (KE) zum Knowledge Management: Entwurf, Aufbau und Wartung von Wissensbanken". KE wurde von ihm als ein expliziter Prozeß vorgestellt, dessen Ziel es ist, die Fachkompetenz der Experten in Wissen umzuwandeln. Im KE werden drei Arten von Wissen unterschieden. Domänenwissen legt die Begriffe der Domäne sowie deren Eigenschaften und Beziehungen fest. Inferenzwissen definiert mögliche Schlußfolgerungen auf dem Domänenwissen. Prozeß- oder Kontrollwissen definiert Heuristiken wie bestimmte Inferenzen zur Lösung einer Aufgabe kombiniert werden können. Voraussetzung für den erfolgreichen Aufbau und die Wartung von Wissenbanken ist die Kapselung von Wissen, die Integration verschiedener Formalisierungsgrade und die Wiederverwendung von Wissensbanken in verschiedenen Kontexten. In der Diskussion wurde darauf hingewiesen, daß zum Aufbau von Wissensbanken typischerweise ein zweistufiges Vorgehen verwendet wird. Zunächst wird das Wissen mit informalen Sprachen definiert und dann in formale Wissensmodelle überführt. Wesentlicher Bestandteil des Wissensmanagement ist der Umgang mit informalen Wissensformaten, da typischerweise nur diese von den Fachexperten verstanden und in der Praxis oft zur Definition von Wissen verwendet werden. Die Definition von Wissensbanken ist ein bilateraler Prozeß und unterscheidet sich daher fundamental vom "Knowledge Mining". Es wurde zudem darauf hingewiesen, daß die Eigenschaft "etwas Vergessen zu können" essentiell für den erfolgreichen Einsatz von Wissensbanken ist. Hierfür existieren derzeit keine geeigneten Lösungen.
Im letzten eingeladenen Vortrag befaßte sich Jörg Desel (Universität Karlsruhe) mit dem Thema "Petrinetze und verwandte Modelle". Er legte den Schwerpunkt seines Vortrags darauf, daß Petrinetze ein wichtiges Bindeglied zwischen anwendungsnahen Sprachen zur Modellierung von dynamischen Prozessen und formalen Ansätzen zur Beschreibung paralleler Prozesse darstellen. Als Beispiele für anwendungsnahe Sprachen wurden u.a. EPKs und UML-Aktivitätsdiagramme genannt (UML ist die von der OMG standardisierte objektorientierte "Unified Modeling Language"). In der anschließenden Diskussion wurde vor allem die Frage erörtert, warum Petrinetze trotz ihrer Formenvielfalt und ihrer unbestreitbaren Vorteile für die Analyse (Simulation, Verifikation) dynamischer Prozeßabläufe nie wirklich weite Verbreitung gefunden haben. Als Gründe wurden u.a. die zu formale Präsentation und die Probleme der Integration mit daten-/objektorientierten Modellierungssichten genannt. Davon ausgehend wurde schließlich das Verhältnis von Statecharts und Petrinetzen erörtert, ohne jedoch eine Übereinkunft über die Stärken und Schwächen der beiden Ansätze zu erzielen.
Im Anschluß an den letzten der eingeladenen sieben Fachgruppenvorträgen
wurden im Rahmen einer allgemeinen Diskussionsrunde Fragen wie "Was
können wir - die einzelnen Fachgruppen - voneinander lernen?",
"Wo sind gemeinsame Defizite?" und vor allem "Was sind gemeinsame
Ziele?" angesprochen. Als Grundlage für eine Beantwortung obiger
Fragen wurde vorgeschlagen, ein gemeinsames Beispiel auszuarbeiten und
mit den Ansätzen der verschiedenen Fachgruppen zu untersuchen. Im
weiteren Verlaufe der Diskussion wurde jedoch klar, daß eine solche
Vorgehensweise nicht nur aufgrund des Zeitmangels und der dabei auftretenden
Koordinationsprobleme zum Scheitern verurteilt ist, sondern zudem einzelne
Fachgruppen sich auf ganz unterschiedliche Anwendungsbereiche konzentrieren,
zum Teil ganz unterschiedliche Phasen der Software-Entwicklung in den Vordergrund
stellen und zudem einzelne Fachgruppe wie EMISA sich nicht mit einem Ansatz
identifizieren lassen, sondern bereits in sich die gesamte Heterogenität
der verschiedenen am Workshop beteiligten Fachgruppen widerspiegelt. Aus
all diesen Gründen erscheint deshalb die Auswahl eines gemeinsamen
Anwendungsbeispiels kaum möglich und zudem der Vergleich sogenannter
"Fachgruppenansätze" nur in sehr beschränktem
Maße überhaupt sinnvoll zu sein. Zu diesem Zeitpunkt wurde die
Diskussion abgebrochen und erst am Vormittag des dritten Tages unter dem
Motto "Gemeinsame Querschnittsthemen" wieder aufgegriffen.
Im ersten Vortrag dieser Sitzung sprach Dietrich de Fries (Informatikzentrum der Sparkassenorganisation Bonn) über "Informations-Systemarchitekturen - Einsatz und Nutzen in der Modellierungspraxis". Inhaltlicher Schwerpunkt dieses Vortrags waren die Pläne des Informatikzentrums der Sparkassen zum Aufbau eines gemeinsamen Metainformationsmodells (bestehend aus einem Vorgehensmodell plus einem Architekturrahmenwerk) für die Softwareentwicklung bei allen Sparkassenverbänden. In der anschließenden Diskussion wurde vor allem die Beherrschbarkeit eines solchen Vorhabens in Frage gestellt, wenn auch die Notwendigkeit zur Vereinheitlichung bislang eingesetzter Begriffsysteme und Vorgehensmodelle unumstritten war.
Im folgenden Vortrag befaßte sich Anita Krabbel (Universität Hamburg) mit der "Aufgabenbezogenen Modellierung von Domänensoftware" am Beispiel eines Pflegeplanungs- und Dokumentationssystems für Krankenhäuser. Sie schlug ein zweistufiges Konzept zur Erstellung eines Domänenmodells vor: (1) Festlegung des abzudeckenden Domänenbereichs anhand des Studiums von Gesamtaufgabe, Strategie und Randbedingungen eines Unternehmens sowie (2) Erstellung des eigentlichen Domänenmodells mit Hilfe von Szenarien. Dieses Konzept wurde von allen Zuhörern aufgrund der engen Einbeziehung künftiger Anwender und des Verzichts auf unnötige Formalismen als praxisnah und praktikabel eingestuft.
Im letzten Vortrag der Sitzung berichtete Peter Pauen (Fernuniversität
Hagen) über die "Modellierung von Hypermedia-Applikationen
mit HyDev". Er schlug zur Modellierung von Hypermedia-Dokumenten
ein spezialisiertes objektorientiertes Modell vor, in dem es spezielle
Kategorien (Stereotypen) von Klassen für räumliche Objekte, aktive
Agenten, etc.) gibt und Klasseninstanzen ein besonderer Augenmerk geschenkt
wird. In der abschließenden Diskussion wurde erörtert, ob es
- angesichts der vielfältigen Unterschiede - sinnvoll ist, WWW- und
CBT-Applikationen (CBT = Computer Based Learning) unter dem Begriff "Multimedia"
zusammenzufassen und wie weit die vorgeschlagene Modellierungssprache mit
stereotypisierten Klassenmodellen von UML zusammenfällt. Schließlich
wurde angeregt, weitere Diagrammarten zur Modellierung dynamischer Verhaltensabläufe
mit einzubeziehen.
Erich Ortner (TU Darmstadt) skizzierte in seinem Beitrag "Normsprachliche Entwicklung von Informationssystemen" einen materialsprachlichen Ansatz zur IS-Entwicklung. Ortner postulierte für die frühe Phase des Fachentwurfs Methodenneutralität, um die Anwender in dieser Phase nicht unnötig mit Konzepten wie Relation, Transaktion, Workflow, Klasse etc. aus speziellen Methoden zu belasten. Schließlich forderte er, daß in der Systementwicklung Begriffe in einer bestimmten Weise normiert werden, um so die Kommunikation zwischen Entwicklern, Anwendern, Management bzw. Geschäftspartnern zu verbessern. Die Normierung der Begrifflichkeit sei dabei ein kontinuierlicher Prozeß. In der Diskussion des Beitrags wurde angemerkt, daß eine Standardisierung der Begrifflichkeit auch problematisch sein kann. Unternehmensweit Begriffe zu normieren (und zu kontrollieren) ist zwar im Vergleich zur Entwicklung eines unternehmensweiten Datenmodells einfacher, erfordert dennoch eine kontinuierliche Schulung aller Anwender und ist, im Vergleich zur Entwicklung eines unternehemensweitem Datenmodells, zwar einfacher, es stellt sich jedoch die Frage, wie einschränkend die Normierung sein soll.
Reinhard Schütte (Westfälische Wilhelms-Universität Münster) kritisierte in seinem Beitrag "Subjektivitätsmanagement bei Informationsmodellen" den vielfach verwendeten rein abbildungsorientierten Modellbegriff, bei dem ein Modell lediglich als Abbild der Realität angesehen wird. Demgegenüber steht der konstruktionsorientierte Modellbegriff, bei dem das Modell als Ergebnis eines Konstruktionsvorgangs durch den Modellierer angesehen wird. Daraus ergibt sich die Forderung, die Subjektivität von Modellen zu berücksichtigen. Zur Reduzierung von Subjektivismen wurde von Schütte die Verwendung von Referenzmodellen vorgeschlagen. Um die Bewertung von Modellen zu ermöglichen, stellte er zudem Grundsätze für die ordnungsmäßige Modellierung vor. Die Qualitätssicherung von Modellen wurde in der Diskussion als fundamentale Aufgabe angesehen, die durch die häufig immateriell beschriebenen und damit schwer faßbaren Sachverhalte erschwert wird. Grundsätze ordnungsmäßiger Modellierung wurden als nützlich angesehen, in der derzeitigen Form als (möglicherweise zu) vage kritisiert. Schütte erläuterte, daß die Grundsätze in Ergänzung zu speziellen normativen Vorgaben für konkrete Sprachen (z.B. UML) zu sehen sind, die derzeit entwickelt werden. Seine Ablehnung der abbildungsorientierten Modellierung stieß nicht bei allen Anwesenden auf ungeteilte Zustimmung.
Der Beitrag "Bestimmung von Objektkandidaten mit Hilfe von formaler
Begriffsanalyse" von Stephan Düwel (Universität Marburg)
befaßte sich mit der Definition von geeigneten Objektkandidaten für
die Bildung von Klassenhierarchien. Die Formale Begriffsanalyse versucht,
mit mathematischen Hilfsmitteln (Verbandstheorie) begriffliches Denken
zu unterstützen. Begriffe werden als Paare aus Begriffsumfang und
Begriffsinhalt behandelt. Auf der Menge der Begriffe kann durch Betrachtung
der Ober-/Unterbegriff-Beziehung eine mathematische Ordnungsrelation gebildet
werden, wodurch ein vollständiger Verband, der sog. Begriffsverband,
entsteht. Zur graphischen Veranschaulichung wird ein Begriffsverband in
einem Liniendiagramm dargestellt, aus dem sich eine mögliche Klassifizierung
ablesen läßt. In der Diskussion wurde gefragt, ob neben der
Ober-/Unterbegriff-Beziehung nicht auch eine Teil-Ganzes-Beziehung wünschenswert
sei. Dazu könnte eventuell ein zweiter Verband eingeführt werden.
Verschiedentlich wurde Skepsis an der Praktikabilität des Ansatzes
geäußert. Das Verfahren ist bisher für "reale Anwendungen"
noch nicht eingesetzt worden. Die Frage nach der Anwendung des umfangreichen
mathematischen Hintergrunds der Formalen Begriffsanalyse bllieb daher offen.
Roland Kaschek (Universität Klagenfurt) forderte in seinem Beitrag "Prozeßontologie als Faktor der Geschäftsprozeßmodellierung" ein Metamodell, das die Definition von Phasen als zusätzliche Abstraktionsebene zwischen elementarer Aktivität und Geschäftsprozeß unterstützt. Innerhalb einer Phase kooperieren hierbei die am Geschäftsprozeß beteiligten Akteure und leisten (kooperationslose) Beiträge zum Prozeß. Dieser Kontribution und Kooperation kann ein Teilziel gegenübergestellt werden, das erreicht werden soll. Entsprechend wird einer Phase ein Subziel und dem Geschäftsprozeß ein (Gesamt-)Ziel zugeordnet. In der Diskussion wurde der Sinn einer Unterscheidung zwischen Prozeß, Phase und Akivität angezweifelt und z.B. vorgeschlagen, Prozesse (rekursiv) durch Sub-Prozesse zu definieren. Dadurch wäre die Definition von zusätzlichen Zwischensichten möglich, die praktische Anwendbarkeit könnte jedoch dadurch möglicherweise erschwert werden. Kaschek wies darauf hin, daß die genaue Bedeutung des Begriffs "Sub-Prozeß" bzw. des verwandten Begriffs "Teil-Prozeß" unklar sei. Allgemein wurde anerkannt, daß die Modellierung von Zielen in Geschäftsprozeßmodellen sinnvoll ist.
Ralf Schamburger (Universität Erlangen-Nürnberg) beschrieb
in seinem Beitrag "Workflow-Operationen als Bereicherung der funktionalen
Dekomposition in Workflow-Schemata" zwei unterschiedliche Ansätze
zur Modellierung von Workflows. In beiden Ansätzen wird durch funktionale
Dekomposition der Arbeitsablauf in Arbeitsschritte zerlegt. Im ersten Ansatz
werden Arbeitsschritte als Sub-Workflows definiert, die aus elementaren
Workflows bestehen. Der Kontrollfluß zwischen den elementaren Workflows
wird explizit in den Sub-Workflows festgelegt. Im zweiten Ansatz werden
die Arbeitsschritte in Workflow-Operationen zerlegt, die jeweils eine Teilaufgabe
beschreiben. Im Gegensatz zu den Sub-Workflows definieren die Workflow-Operationen
keinen Kontrollfluß. Dadurch hat der Anwender die Möglichkeit,
aus den angebotenen Workflow-Operationen eine oder mehrere in beliebiger
Reihenfolge auszuwählen. Dieser Vorteil wurde in der Diskussion weiter
vertieft und fand weite Zustimmung. Die Anwender werden dadurch weniger
stark in ihrer gewohnten Arbeitsweise eingeschränkt und gewinnen zusätzliche
Auswahl- und Entscheidungsmöglichkeiten. Als problematisch wurde
allerdings angesehen, daß der vorgestellte Ansatz bisher noch keinerlei
methodische Unterstützung vorsieht. Abschließend wurde darauf
hingewiesen, daß sehr ähnliche Ansätze bereits vor einigen
Jahren vorgeschlagen wurden.
Im erstem Vortrag der letzten Sitzung des Workshops stellte Wieland Schwinger (Universität Linz) mit "A Comparison of Role Mechanisms in Object-Oriented Modeling" einen umfassenden Vergleich sogenannter rollenbasierter Modellierungsansätze vor. Im Kern ging es dabei darum, daß heute weitverbreitete OO-Modellierungs- und Programmiersprachen voraussetzen, daß ein Objekt über seine gesamte Lebenszeit hinweg Instanz genau einer Klasse ist. Bei den vorgestellten Ansätzen kann hingegen ein Objekt im Laufe seiner Lebenszeit verschiedene Rolle (wie etwa Student oder Angestellter oder ... ) annehmen und wieder ablegen. In der anschließenden Diskussion wurde kontrovers erörtert, ob sich rollenbasierte Ansätze aufgrund ihrer höheren Komplexität durchsetzen werden. Zudem wurde auf das Problem der Unterscheidung zwischen Objektassoziationen und Objektrollen sowie auf die Querbezüge zur Schemaevolution in Datenbanken hingewiesen.
Im zweiten Vortrag der Sitzung befaßte sich Stefan Joos (Universität Zürich) mit dem UML-Konzept der "Stereotypen und ihrer Verwendung in objektorientierten Modellen". Er schlug eine Unterteilung von Stereotypen in "rein dekorativ" für die Veränderung der Darstellung von Klassendiagrammen, "deskriptiv" für die Hinzunahme informeller Verwendungshinweise, "restriktiv" für die Hinzunahme formalisierter Verwendungseinschränkungen und "redefinierend" für die vollständige Umdeutung von Klassendiagrammelementen vor. Sein Fazit, daß rein dekorative Stereotypen eher auf der Ebene eines CASE-Tools abgehandelt werden sollten und daß der Einsatz redefinierender Stereotypen dem Ziel einer gemeinsamen Modellierungssprache mit wohlverstandener Semantik zuwiderläuft, fand allgemeine Zustimmung. Darüber hinaus wurde darauf hingewiesen, daß Stereotypen in ihrer jetzigen Form eine Art erweiterbares Metamodellkonzept des kleinen Mannes für die Modellierungssprache UML sind.
Im letzten Vortrag des Workshops sprach Mario Winter (Fernuniversität
Hagen) über die "Kombinierte Validierung von Use Cases und
Klassenmodellen". Er kritsierte zunächst eine Reihe von Mängeln
klassischer Use-Case-Diagramme (wie fehlende Modellierung des Kontextes
von Operationen, unpräzise Definition von extends- und uses-Beziehungen).
Anschließend führte er sogenannte Use-Case-Graphen ein, die
einen gleitenden Übergang von Kontrollflußdiagrammen (Aktivitätsdiagramme
von UML) zu Klassendiagrammen und den damit assozierten Objektinteraktionsdiagrammen
unterstützen. In der abschließenden Diskussion wurde es begrüßt,
daß auf diese Weise ein Bindeglied zwischen dem Einsatz von Use Cases
in den frühen Phasen der OO-Modellierung und später eingesetzten
Diagrammtechniken geschaffen wurde. Eine lebhafte Diskussion entspann sich
allerdings an dem Vorschlag die grobgranulare Modellierung von Aktivitäten
(Prozessen) auf der Ebene der Use-Case-Diagramme und die feingranulare
Modellierung solcher Abläufe allein auf der Ebene der Objektinteraktionsdiagramme
durchzuführen. Der Wunsch, auf beiden Ebenen das Konzept der schrittweisen
Verfeinerung zur Verfügung zu haben, fand hingegen allgemeine Zustimmung.
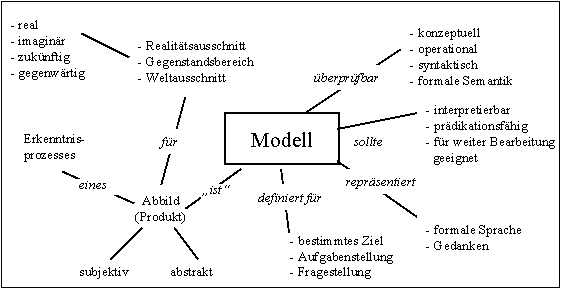
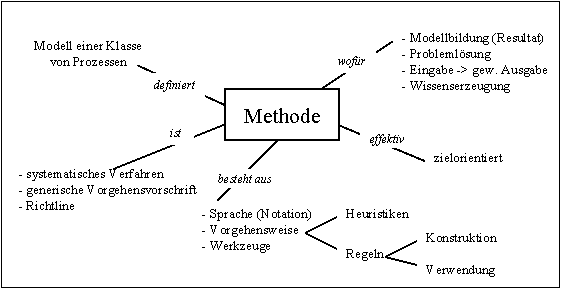
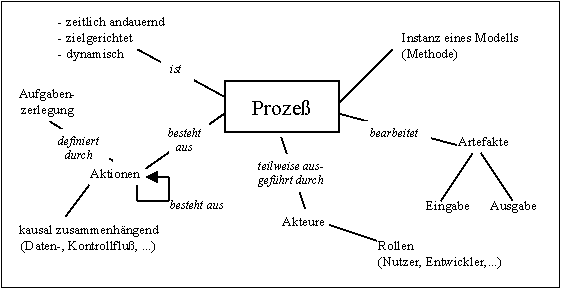
Während des Workshops hatte jeder Workshopteilnehmer die Gelegenheit die Begriffe "Modell", "Methode" und "Prozeß" in schriftlicher Form unter der Verwendung von jeweils max. 12 Wörtern zu definieren. Die Auswertung der insgesamt über 25 Definitionen zeigte eine prinzipelle Übereinstimmung, wobei in den einzelnen Definitionen jedoch unterschiedliche Aspekte der Begriffe betont wurden.
Die in den drei folgenden Bildern dargestellten Begriffsdefinitionen fassen die einzelnen Definitionen sowie die Diskussion gegen Ende des Workshops zusammen. Zur Definition des Begriffs "Modell" sei angemerkt, daß durchaus alternative Definitionen angesprochen wurden, z.B. der mathematische Modellbegriff (mögliche Interpretation einer Theorie) oder Modell einer Sprache.
Begriffsdefinition: Modell
Begriffsdefinition: Methode
Begriffsdefinition: Prozess
Während der abschließenden Dskussion wurden zunächst die während des Workshops erkannten fachgruppenübergreifenden Gemeinsamkeiten thematisiert. Dazu gehörte u.a. die von allen Teilnehmern geteilte Einschätzung, daß komponentenbasierte Softwareentwicklung und der Einsatz domänenspezifischer Modelle und Vorgehensweisen von enormer Bedeutung sind. Des weiteren herrschte Einigkeit darüber, daß die Entwicklung von allumfassenden Methoden, Modellierungssprachen oder gar Referenzmodellen kaum realistisch ist. Als Ausweg wird die Entwicklung von Methodenfragmenten, problemspezifischen Modellierungsprachen und Referenzmodellen für wohldefinierte Teilbereiche sowie deren ("ad hoc") Kombination angesehen. Für die Modellierung von statischen Strukturen haben sich allgemein verschiedene Varianten von ER-Diagrammen (Klassendiagrammen) durchgesetzt. Zudem wird der Metaisierung (Metamodellbildung) eine stetig wachsende Bedeutung zugemessen.
Anschließend wurde das wichtige Thema der Identifikation und gemeinsamer Bearbeitung fachgruppenübergreifender Fragestellungen diskutiert und damit (indirekt) die Diskussion des Vortags über das gemeinsame Studium eines oder mehrerer Beispiele fortgesetzt. In Übereinstimmung mit der allgemeinen Zielsetzung der GI, ihre Strukturen flexibler zu gestalten, wurde es als sinnvoll erachtet, eng umgrenzte Themenbereiche von allgemeinem Interesse zu identifizieren und in zeitlich begrenzt existierenden Arbeitskreisen zu bearbeiten.
Als mögliche Querschnittsthemen wurden u.a. terminologische Probleme, Strukturierungs- und Abstraktionskonzepte sowie die Nachvollziehbarkeit von Modellerstellungsprozessen genannt. Besonders hervorgehoben wurde jedoch der Punkt "domänenspezifische Modellierungssprachen". Die Ableitung solcher Sprachen aus einer gemeinsamen Basissprache oder mit Hilfe eines gemeinsamen Rahmenwerkes bietet die Chance, ansonsten in Widerspruch stehende Anforderungen an eine Modellierungssprache wie "leicht verständlich" versus "möglichst mächtig" oder "problemadequat" versus "breit einsetzbar" in Einklang zu bringen.
Als Ziel wurde zudem die Entwicklung einer einheitlichen "Modellierungslehre" angesprochen. Die Vermittlung von einheitlichen Konzepten und Denkweisen an die Studierenden wurde als unerläßlich für den weitverbreiteten, erfolgreichen Einsatz von Modellierungstechniken angesehen.
Alle Teilnehmer empfanden die in den Vorträgen dargelegten unterschiedlichen,
aber teilweise doch stark überlappenden Blickwinkel auf das Themengebiet
sowie die zahlreichen Diskussionen sehr fruchtbar. Es wurde einvernehmlich
beschlossen, die fachgruppenübergreifende Diskussion zum Thema "Modellierung"
im folgenden Jahr wiederum in Form eines kleineren Workshops fortzusetzen.
Für das Jahr 2000 wurde darüberhinaus bereits die Organisation
der Tagung "Modellierung 2000" ins Auge gefaßt, die ggf.
mit den Hauptjahrestreffen einzelner Fachgruppen kombiniert werden wird.
[PSV 98] K. Pohl, A. Schürr, G. Vossen: Modellierung '98 (Proceeding), Bericht Nr. 6/98-I, Angewandte Mathematik und Informatik, Universität Münster; auch erschienen als CEUR Workshop Proceedings, Vol-9, http://SunSITE.Informatik.RWTH-Aachen.DE/Publications/CEUR-WS/Vol-9/